深度学习用于机械臂抓取
Mahler,J.,Liang,J.,Niyaz,S.,Laskey,M.,Doan,R.,Liu,X.,Ojea,J.A.andGoldberg,K.,2017.Dex-Net2.0:DeepLearningtoPlanRobustGraspswithSyntheticPointCloudsandAnalyticGraspMetrics.arXivpreprintarXiv:1703.09312
1. 抓取的难点:
抓取是manipulation里最常见的问题之一。早期对抓取的研究有很多在判定一个稳定的抓取是否形成,比如是否满足force closure (手指与物体的接触点是否可以产生抵抗任意方向、大小的外力)。除了通常意义上的稳定抓取,另一种限制物体位置的方式是caging,即通过放置手指,让物体无法离开这一区域。
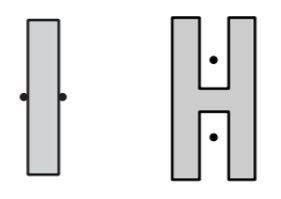
图1. 抓取示例1:图中黑点代表手的位置。左:摩擦系数不为零时,形成force closure;右:caging
Force closure的判定方法方法很早就有了,左右一种简单直接的抓取算法思路如下:
1.1抓取算法1.0
- 随便选一个抓取位置.(比如在物体表面采样一堆点,有很多方法)
- 判断这个抓取的位置能够形成force closure
- 如果是,执行这个抓取;如果否,回到第一步
这个方法计算量不大,对于多数物体你可以采样几十组点就轻松找到一个不错的抓取。看上去抓取问题就被解决了。但是这只是解决了最简单的清醒,即:
- 物体形状已知
- 对物体位置的感知完全精确
- 环境中没有障碍物
如果这算个假设都被满足,这样的抓取40年前的研究者们已经解决了。然而对于实际中的问题而言,这些假设往往很难满足,而且一旦离开了这些假设,抓取问题可以变得任意困难,比如“抓取任意形状的物体”,“在没有感知的情况下抓取物体”,“把压箱底的书取出来”,也正因如此,对抓取的研究才至非常活跃。
2.问题描述
这篇文章尝试解决基于点云的平面抓取问题。机器人使用二指平行抓手(parallel gripper),物体放在没有障碍物的平面上,对物体的感知来自于深度摄像头自上而下拍摄的一张图片以及从中获取的物体点云数据。

图2
抓取过程被简化为“放下,合拢手指,拿起”三步,机械手始终手指向下,整个抓取动作只用三个量描述:手掌平面位置x,y以及手指朝向。算法要做的就是根据摄像头数据,给出一组这样的动作参数以实现抓取。
基于深度摄像头的抓取,传统方法中最可靠的方式是根据点云数据进行图像分割,物体识别以及物体的位姿估计,再根据物体几何结构选择合适的抓取位置。这种方法要求物体模型已知,同时,在衡量抓取位置优劣时要考虑到感知系统的不确定性,而非简单滴计算是否形成force closure:
2.1 抓取算法2.0
从图像中识别出物体种类,估计物体位姿。
根据物体几何结构随便选N个抓取的位置。
根据某个评价函数,为每个抓取位置打分。
选择得分最高的抓取位置执行。
传统方法的主要缺点是环节多,每一环都有不少参数要调整,因此整个系统使用起来的人工复杂度比较高。这也催生了近年来比较火的基于深度学习进行抓取的方法,采用卷积神经网络来描述一个从图像直接到抓取位置的映射:
2.2 抓取算法3.0
- 从图像直接获取抓取位置并执行
比如CMU RI的Gupta组,把抓取位置进一步简化为仅判断抓取的角度,并使用多达5万次机器人抓取实验来训练所需的神经网络2。Google DeepMind 尝试从一堆物体中进行抓取,场景更复杂,因而也使用了更大的数据量(超过八十万次抓取,十几台机械臂花了两个多月才收集完数据)3。这种方法看上去直接,然而实际使用起来采数据所花的人力物力远超过传统方法。
为了让仿真数据能用来训练神经网络,这篇文章有几个值得注意的地方:
- 在仿真中认为引入模型误差,这样训练出来的结果起码能对付人工引入的噪声;
- 定量衡量一个抓取的抗干扰能力,以此作为依据在多个候选解中取最优;
- 把抓取表述成一个规模合适的问题,不考虑复杂的抓取动作。不考虑背景干扰或遮挡,最重要的是不做端到端,神经网络不需要直接输出抓取位置,而是仅需要做一个评价函数,对一个给定的抓取位置打一个分数。问题的复杂度降低后,仿真的失真带来的不利影响也随之变小。使用这样训练出来的神经网络,相比算法2.0我们仍可以省略掉步骤一,于是有了最终版算法:
2.3 抓取算法4.0
- 在点云上随便选N个抓取的位置。
- 根据训练好的CNN评价函数,为每个抓取位置打分。
- 选择得分最高的抓取位置执行。
下面就详细介绍神经网络评价函数是如何得到的。
3. 抓取动作的神经网络评价函数
为了训练评价函数神经网络,作者使用仿真的方式生成训练数据

图3.训练数据使用的部分物体模型
将1500个不同物体的3D模型,随机摆成各种姿态并渲染出深度摄像头拍摄到的点云。在每种姿态下再随机生成最多100个抓取位置。摩擦力模型使用库伦摩擦,摩擦系数按正太分布随机选取,最终总共得到多达6,750,000个不同的点云+抓取位置组合。最后将每一张点云图进行旋转缩放,让每张图片中的抓取位置都在中心,这样就不必额外为抓取位置增加输入的维度。
对于每一个训练数据,使用[4]提出的抓取鲁棒性标准对其抓取质量进行衡量,得到的分数作为label。
这些数据被用来训练一个抓取质量衡量网络(Grasp Quality CNN)。其结构比较特别,输入的点云数据经过4层ReLU单元的卷积层,和抓取高度z一同再经过三层全连接层。注意这里的抓取高度z并不包含在训练数据里,而是在手抓中心和桌面间随机选取的。这套算法并不主动选取抓取高度。网络的输出是对所输入的抓取质量的评估值,一个标量。

图 4. GQ-CNN结构
CNN的训练使用SGD,和很多其他神经网络的训练一样,需要加上一堆各种各样的trick才能训练处好的效果,比如梯度加momentum、按什么分布选取权重初值、分批次加噪声等等,这些都需要大量调试的工作。

图 5. 第一层卷积层训练后得到的权重
4. 实验
4.1 实验一:抓取3D打印物体

图 6. 实验平台采用ABB柔性写作机器人YuMi,和一个AutoLab自己开发的评星夹手,这个机械手上有一些传感器。
在第一个实验中,作者从物体模型库中选择了8个形状较为复杂的3D打印出来的物体作为抓取测试对象。为了与GQ-CNN进行比较,作者好实现了包括随机抓取和传统方法(算法2.0)在内的五种方法,每种方法对每个物体抓取10次。

图 7. 实验一使用的物体
结果如下,在模型已知的情况下,传统方法(REG-K)取得了最高的成功率(95%),而作者提出的神经网络方法GQ的成功率略低一些(93%)。而且传统方法95%的成功率是在步骤一物体识别率仅为93%的情况下得到的,也就是说如果明确知道被抓的物体是哪一个,传统方法也许能保证抓取。
不过神经网络方法的一个明显好处是在线计算速度快,用时是REG-K的三分之一。

4.2 实验二:抓取未知物体
一个更有意思的实验是抓取位置物体。作者选取了10个不在模型库中的常见物体用于测试,这些物体的形状、材料、重量各不相同,如下图所示:

作者同样测试了很多方法,面对形状未知的物体,深度学习的方法取得了很好的效果(80%成功率)。而传统的REG因为依赖模型,在模型不对的情况下完全没法发挥作用,成功率最低(52%)。IGQ是不依赖模型的传统方法,直接在图像识别到的物体轮廓上找抓取点,获得了60%的成功率。

5. 评论
这篇文章的特色是使用深度学习的方式取代了传统方法中较困难但问题规模有限的一环,结果是让仿真数据变得有用,并且获得了泛化能力。
这篇文章同大部分使用深度学习做抓取工作相同的一点是,都把抓取问题本身简化到非常容易的程度了,不具备太多代表性。比如在这篇文章的实验环境下,即使随机抓取也有高达58%的成功率。DeepMind的抓取实验,随机抓取也有11%的成功率。约束少,不确定程度较小,这种情况下往往存在朴素而有效的解决方案,比如上个大小合适的吸盘。
还有很多抓取问题,其解空间相对于动作空间是非常非常小的,比如感知系统误差较大的情况,比如从一堆摞在一起的物体中取出特定的一个。
参考文献:
[1] From Caging to Grasping, Alberto Rodriguez, Matthew T. Mason and Steve Ferry
[2] Supersizing Self-supervision: Learning to Graspfrom 50K Tries and 700 Robot HoursLerrel Pinto and Abhinav Gupta
[3] Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection
[4] Large-Scale Supervised Learning of the Grasp Robustnessof Surface Patch PairsDaniel Seita, Florian T. Pokorny, Jeffrey Mahler, Danica Kragic, Michael Franklin,John Canny, Ken Goldberg